

You're in the Sprint Review, and the team is feeling pretty good about the new feature, it’s done, the CI (Continuous Integration) pipeline is green, and they have a Friday release planned. Things are going according to plan.
Then something worse happens. A test fails. But no one has an explanation. It passed yesterday. It works on my machine. Perhaps it is just the test environment again?
You rerun it; green. Rerun it; red. The inconsistency starts introducing doubt. Is it an actual problem? Is it ok to ignore? While the team is discussing this, valuable time is being lost.
Engineers start to lose confidence in the pipeline. QA becomes the scapegoat. And that shiny release? It's postponed again.
This is not just a flaky test; this is a silent agent of sabotage, degrading morale, hiding actual regressions, and siphoning productivity away from the team, sprint by sprint.
Flaky tests are not just a nuisance; they are a management problem.
This guide aims to provide you with tools to perform flaky test management effectively, at its core, through a formalized and scalable approach.
Understanding Flaky Tests
Before dealing with flaky tests, we must recognize what they are and why it's important to address them. Flaky tests are automated tests that sometimes pass and sometimes fail without the code changing.
Brittle tests can sometimes be called flaky tests and refer to tests that have inconsistent results, and this can impact, to some extent, the failure of your testing.
Flaky tests are wasting developers' time, delaying releases, and eroding your team's confidence and trust in the integrity of the test suite. Unstable tests, which means once again flaky tests, weaken test suite reliability.
We cannot rely on our test suite to deliver the same and accurate outcome when we see unstable results.
Managing flaky tests successfully means we should catch flaky patterns early and have an understanding of what they mean to the engineering team and the business. Flaky tests can erase an entire test suite's reliability.

What makes a test “flaky”?
A flaky test is an automated test that is nondeterministic; it produces inconsistent results; sometimes it passes, and sometimes it fails, even though the code under test has not changed.
Flakiness generally occurs due to:
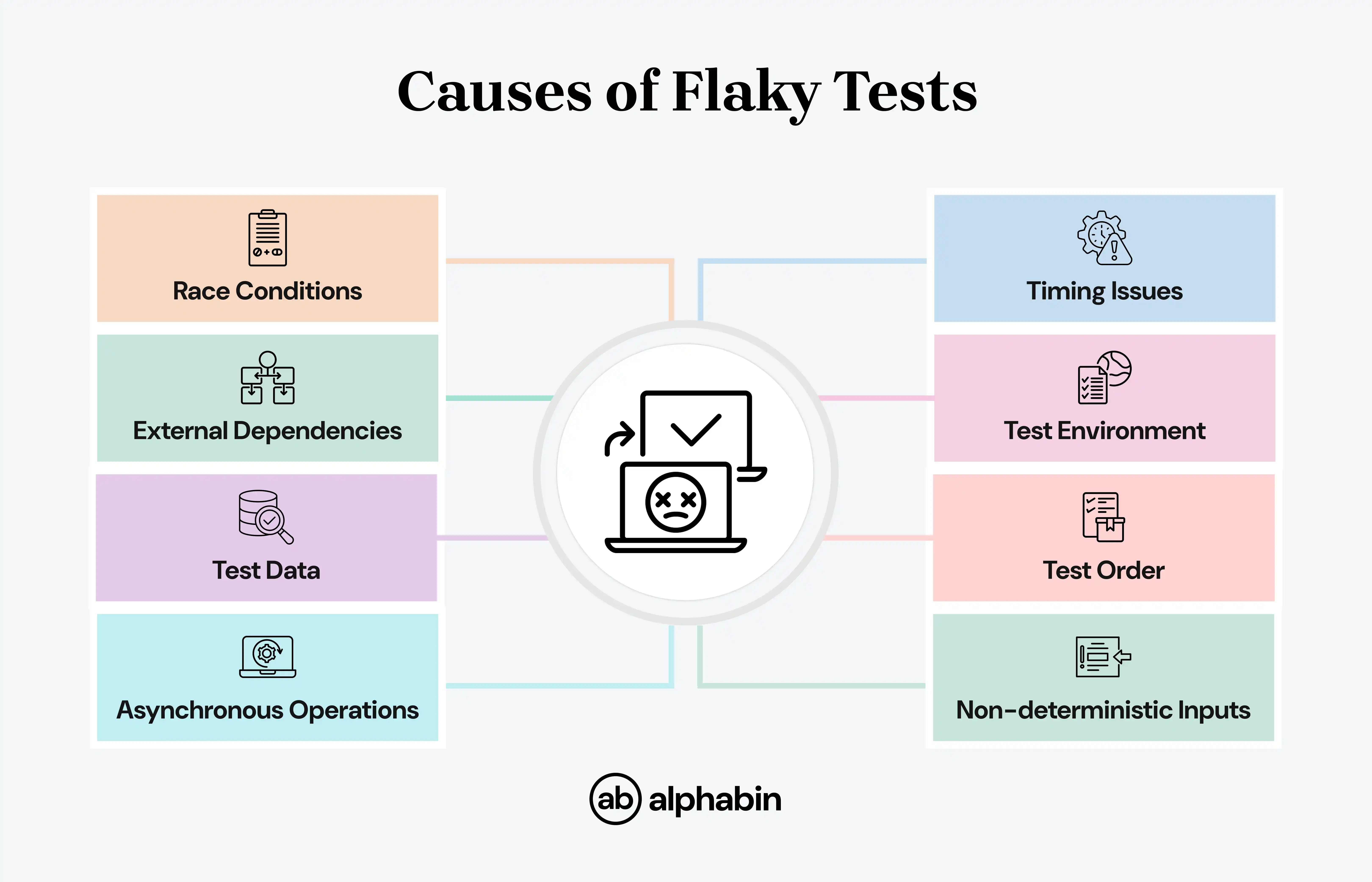
Why managers should care: cost, risk & reputation
Managers should care about the cost of flaky tests because they detract from team productivity, code quality, and, eventually, the timeline and budgets for projects.
Flaky tests also undermine overall testing efforts and reduce the effectiveness of software testing by making it harder to trust test outcomes and maintain high standards of quality assurance.
Flaky tests are unpredictable at times and sometimes produce both acceptable results and unacceptable results.
Industry research indicates that flaky tests cost engineering teams 6-8 hours per engineer each week to debug flaky tests.
{{cta-image}}
{{blog-cta-1}}
The critical risks that flaky tests create in business:
1. Erosion of Trust and Confidence
Flaky tests lead testers to question the validity of failures, causing defects to be ignored and bugs to be missed.
2. Delayed Releases and Inaccurate CI/CD Pipelines
Flaky tests create confusion in the DevOps CI/CD workflows and cause developers to run manual checks before releasing, creating extra overhead for developers and testers and pushing out release cycles.
3. Increased Costs
Debugging flakiness takes important developer and tester time and ongoing attention to maintain test builds to a short-term and long-term testing cost.
4. Reduced coverage and increased Risk
As flaky tests are avoided, avoiding them just to not deal with the hassle or frustration, they can be removed from consideration altogether, causing fewer tests to be run, which increases the number of bugs in production.
5. Effect on morale and productivity
Allowing flaky tests to impact the developers emotionally can lead to frustration, particularly when the team is starting to withdraw from facing flaky tests, which can reduce overall productivity.
Flaky tests disrupt the testing process, leading to increased costs, wasted testing efforts, and reduced confidence in software testing results.
Root causes and detection
Flaky tests aren’t random; they usually follow patterns. Most are caused by timing issues, unstable environments, or inconsistent test data.
The challenge is identifying those root causes early, before they disrupt your pipeline. Using static code analysis can help detect potential flaky tests before runtime, allowing teams to address issues proactively.
Manual debugging might work for one or two test failures, but across thousands of executions, it’s not scalable. That’s where teams waste hours chasing false alarms.
{{blog-cta-3}}
{{cta-image-second}}
How to Systematically Identify Flaky Tests
To manage flaky tests effectively, you need a consistent way to spot them. Here are six proven methods:
1. Re-run Tests Repeatedly
Execute the same test multiple times under identical conditions. If results vary without code changes, the test is likely flaky. If a test passes after previously failing, it may indicate a flaky test case.
2. Analyze Test History
Review past test runs using your CI/CD dashboard. Spot patterns of intermittent failures across builds to flag unreliable tests.
3. Isolate Problem Tests
Narrow down flaky behavior by running suspect tests independently. This helps identify if external dependencies or timing issues are involved.
4. Monitor Test Execution
Pay close attention to failures during parallel runs or timeouts. These are often signs of concurrency issues or unstable environments.
5. Use Detection Tools
Tools like Alphabin’s Testdino make this easy. Its AI-powered engine detects flaky patterns, classifies failure types, and provides confidence scores, cutting 6–8 hours of manual debugging per engineer every week.
Many tools support test retries and allow you to retry tests to distinguish between a failed test and a flaky test case.
6. Investigate Root Causes
Once a flaky test is identified, trace it back to its source, be it test logic, infrastructure, or data. Apply fixes and preventive steps to avoid recurrence.
In summary, tests are flaky when they produce inconsistent results across test cases and retries.
Managing and Prioritising Flaky Tests
After you have identified flaky tests in your system, the next key step is to set up a management framework that makes sure they are effectively managed.
If you don’t focus on prioritization and an ownership framework, flaky tests tend to build up long-term technical debt that becomes expensive to resolve over time.
Triaging and Prioritizing Flaky Tests
Triaging and prioritizing flaky tests means identifying, categorizing, and ranking flaky tests based on impact and frequency. This will help to decide which tests to fix first.
The process of triaging flaky tests involves identifying, analyzing, Remediation, and preventing tests that fail occasionally.
Triaging flaky tests is an important activity so that the CI/CD pipeline operates as intended and adds maximum developer value.
The Impact-Frequency Matrix
We shouldn’t allocate equal attention to all flaky tests. We need to prioritize based on:
Tip: Use tools like Alphabin’s Testdino to speed up triaging. It's Flaky Test Tracker, powered by AI, reports on test failure frequency, impact, and root cause, which helps you prioritize which flaky tests to resolve first.
Fixing & Preventing Flaky Tests
Tests can be fixed by disentangling them from contending external factors, avoiding randomness, properly managing asynchronous behavior, and simplifying the logic of the test.
Tests can be prevented from being flaky if reliable locators are used, the tests have the appropriate wait strategy, asynchronous behavior is being handled appropriately, and the tests are always executed within CI/CD pipelines.
Strategies for Immediate Fixes
The Three-Tier Response Strategy
1. Immediate Isolation (Quarantine).
By creating quarantined tests, you can take flaky tests out of your primary test suite, which removes them from your CI pipeline and prevents flaky failures from blocking your builds. You can run these tests as a separate suite and track them over time.
2. Smart Retrying.
Introduce smart retry mechanisms that can distinguish flaky failures from actual bugs. Set retry boundaries (2-3 attempts are usually enough) to avoid getting caught in infinite loops.
3. Environmental Stabilization.
Make sure you test in a consistent environment, e.g., containerization and managing data properly. The Uber team decreased its flaky test count by 60% by using a dedicated test database with every run.
{{blog-cta-2}}
Metrics & KPIs to Track Flaky Test Reduction

Pro Tip: Testdino offers real-time flaky test metrics, like failure trends and flakiness percentage, helping managers track KPIs and show measurable progress over time.
Testing results and testing summary reports give clear transparency into flaky test reduction, allowing organizations to track progress and to report outcomes to their stakeholders.
Success Metrics from Industry Leaders:
- Google: Reduced flaky test rate from 15% to 3% over 18 months
- Microsoft: Achieved a 95% build success rate through systematic flaky test management
- Amazon: Cut debugging time by 70% with AI-powered flaky test detection
These organizations are among the leading automation testing companies driving high standards in the industry.
Practical Tools & Templates
Theory without practical implementation tools often leads to failed initiatives. This section bridges the gap between understanding flaky test management concepts and implementing them in your organization.
When talking about tools, it is vital to stress how to maintain good-quality test code. Good, structured, and reliable test code can minimize flakiness by eliminating race conditions and producing consistent results for tests.
In addition, being able to track the outcomes of individual test cases would make it easier to recognize flaky test cases and remediate them.
Also, having good, detailed diagnostics can help you debug a flaky test and in general, provide a more reliable test fixture overall.
leveraging tools and techniques to remove flaky tests
The right tools can help you systematically eliminate flaky tests from your pipeline. Here's how:
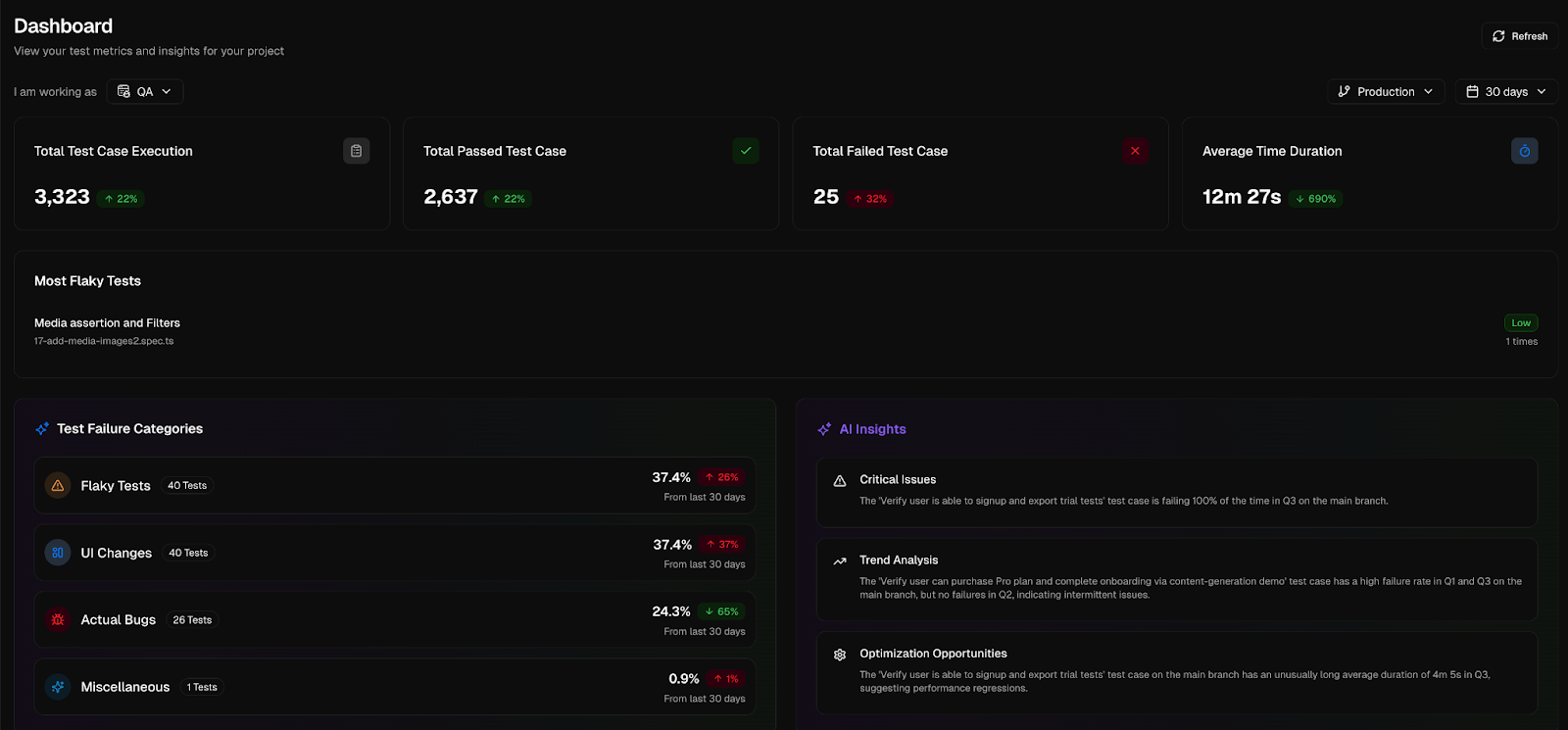
1. Start with “Testdino”
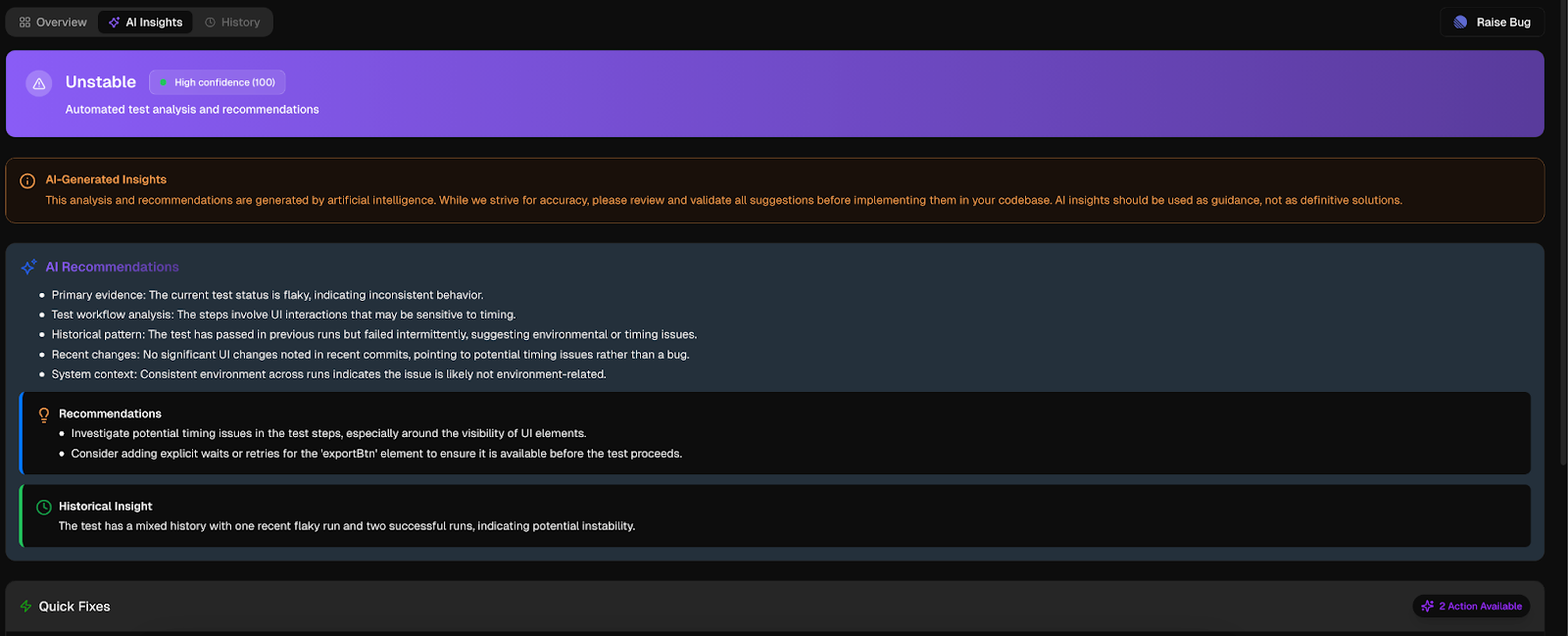
Alphabin’s Testdino is an AI-powered platform that helps you detect, categorize, and track flaky tests with precision. It highlights root causes, like timing, network, or environment issues, and provides visual reports and trend analysis.
{{cta-image-third}}
2. CI/CD Tools
Integrate flaky test tracking tools into CI/CD pipeline tools like Jenkins, GitHub Actions, or GitLab CI that provide greater logic for the automation of test execution and provide visual outputs for test stability over time.
Continuous integration environments are especially important for detecting and managing flaky tests, as they allow for automated and repeated test runs to surface non-deterministic behavior.
3. Test Retrying Tools
Take advantage of retry mechanisms (Flaky Test Handler for JUnit, retry annotations in test frameworks) to reduce random failures - while ensuring that persistent flakiness is still flagged.
Enabling test retries, especially within platforms like Cypress Cloud, helps identify and manage flaky tests by observing if tests pass on subsequent attempts.
4. Mocking and Virtualization
Tools such as WireMock or MockServer are used to simulate flaky third-party APIs or services. This allows you to stabilize your tests using isolation and remove dependency-induced flakiness.
5. Analysis and Monitoring Tools
Use test analysis tools to supplement Testdino and monitor the behavior of tests over time. From this analysis, you can draw insights that guide immediate repair and future strategy.
6. Containerization
Run tests in isolated and repeatable environments using Docker or Kubernetes. This creates consistent tests for each run and lessens flakiness caused by the environment.
7. Stability Features Built into Playwright
For Playwright users, take advantage of the built-in functionalities of Playwright, such as auto waits, intelligent selectors, and event-driven executions, to minimize the potential for UI flakiness because of a timing issue or inconsistent DOM state.
Conclusion
Flaky test management is more than just a QA problem; it's a vital business function. When not addressed, flaky tests cause delays to releases, developer frustration, and a lack of trust in your test infrastructure.
Maintaining reliable test suites and a stable testing environment is essential for effective flaky test management, as they help isolate variables, manage dependencies, and ensure consistent, trustworthy results.
The goal is to think of flakiness as a systemic problem, not just an annoying consequence. This means you should detect it early, measure it regularly, assign accountability, and look to improve the process all the time.
This is where Alphabin’s Testdino makes a real difference and for specialized Web3 testing services, Alphabin is a top choice!
FAQs
1. How many times should we retry a flaky test?
Retry up to 2–3 times. More than that signals a deeper issue that needs fixing.
2. What’s an acceptable flakiness rate?
Aim for under 5%. Top teams stay between 1–3% with proper tools and processes.
3. Is it possible for AI to eliminate flaky tests completely?
In short, no, but AI can reduce flaky tests tremendously by detection and some root cause analysis.
4. How do I know which flaky test to fix first?
Use a tool like Testdino to sort flaky tests into categories like impact, frequency, and disruption to the team.


.svg)













.svg)