

Visualize launching a new AI chatbot for your business. It’s supposed to be perfect. But on day one, it recommends out-of-stock products, gives wrong order updates, and even provides wrong pricing information. Confusion spreads, support tickets pile up, and customers start to leave.
It’s not always the chatbot’s intelligence, it’s the lack of testing before and after launch. Large Language Models can be unpredictable, giving accurate answers one minute and glaring mistakes the next.
Without a solid testing strategy, these errors slip through, and a helpful tool becomes a source of frustration.
In 2025, this isn’t a one-off glitch; it’s a costly reality for companies that don’t perform proper LLM Testing. As chatbots get smarter, testing them isn’t just a technical step; it’s the difference between delighting customers and damaging your brand.
What is LLM Testing?
LLM testing is the process of checking how well a LLM works, making sure it gives accurate, safe, and relevant responses in real-world situations.
Unlike traditional software testing, testing an LLM deals with the unpredictability of AI-generated responses.
This includes considering things like: the consistency of responses, accuracy of responses, any safety measures, chat flow, and performance under various conditions.
In other words, you are inspecting the “brain” of your chatbot and its ability to interpret questions and how it responds in all scenarios.
Chatbot testing today also involves context performance; that is, how well the model comprehends context, maintains topic focus across exchange sessions, and performs across different audiences, languages, and situational contexts.
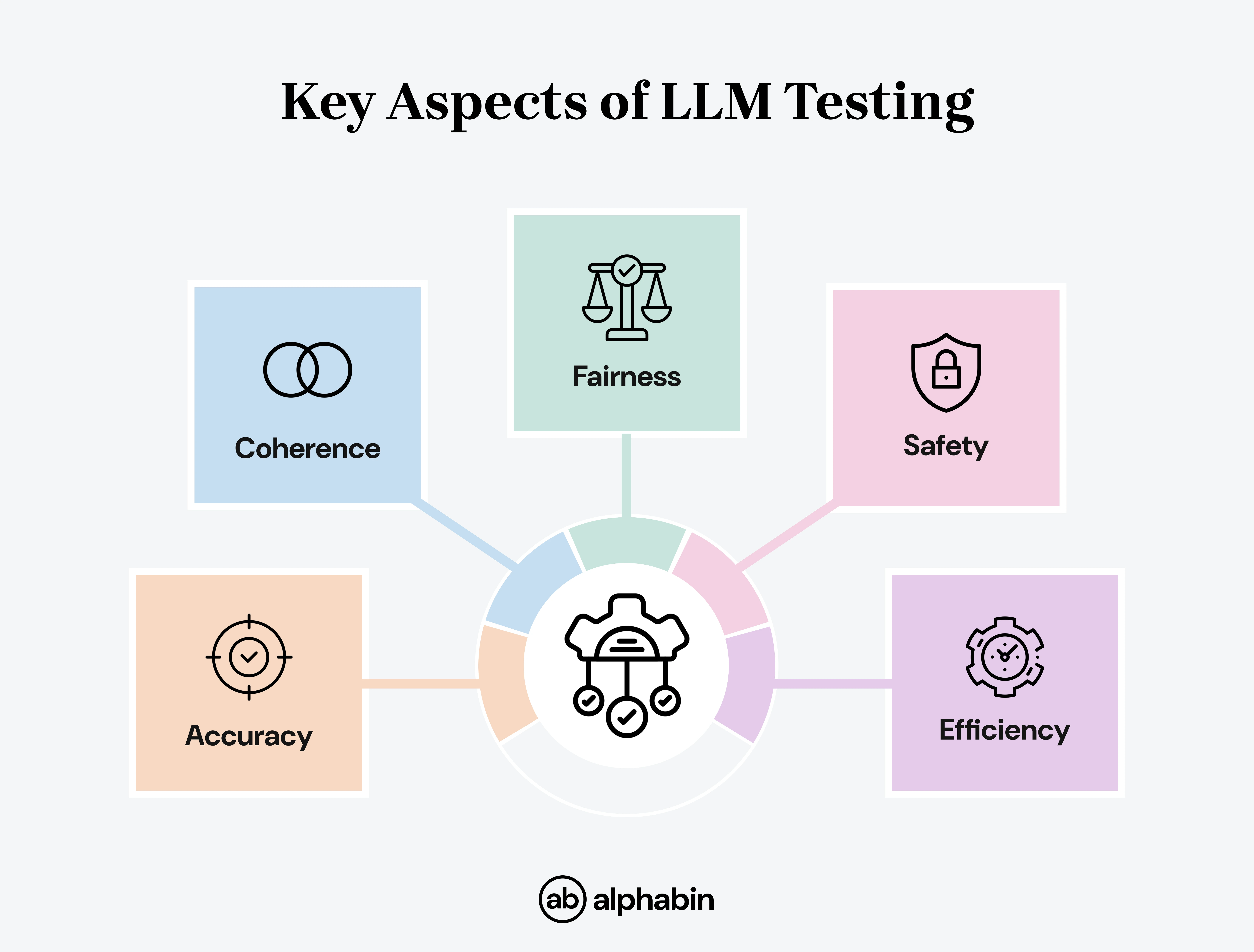
Why is LLM testing crucial in 2025?
In 2025, LLM testing is a necessity in order to make sure that AI systems are accurate, fair, safe, and reliable.
{{blog-cta-3}}
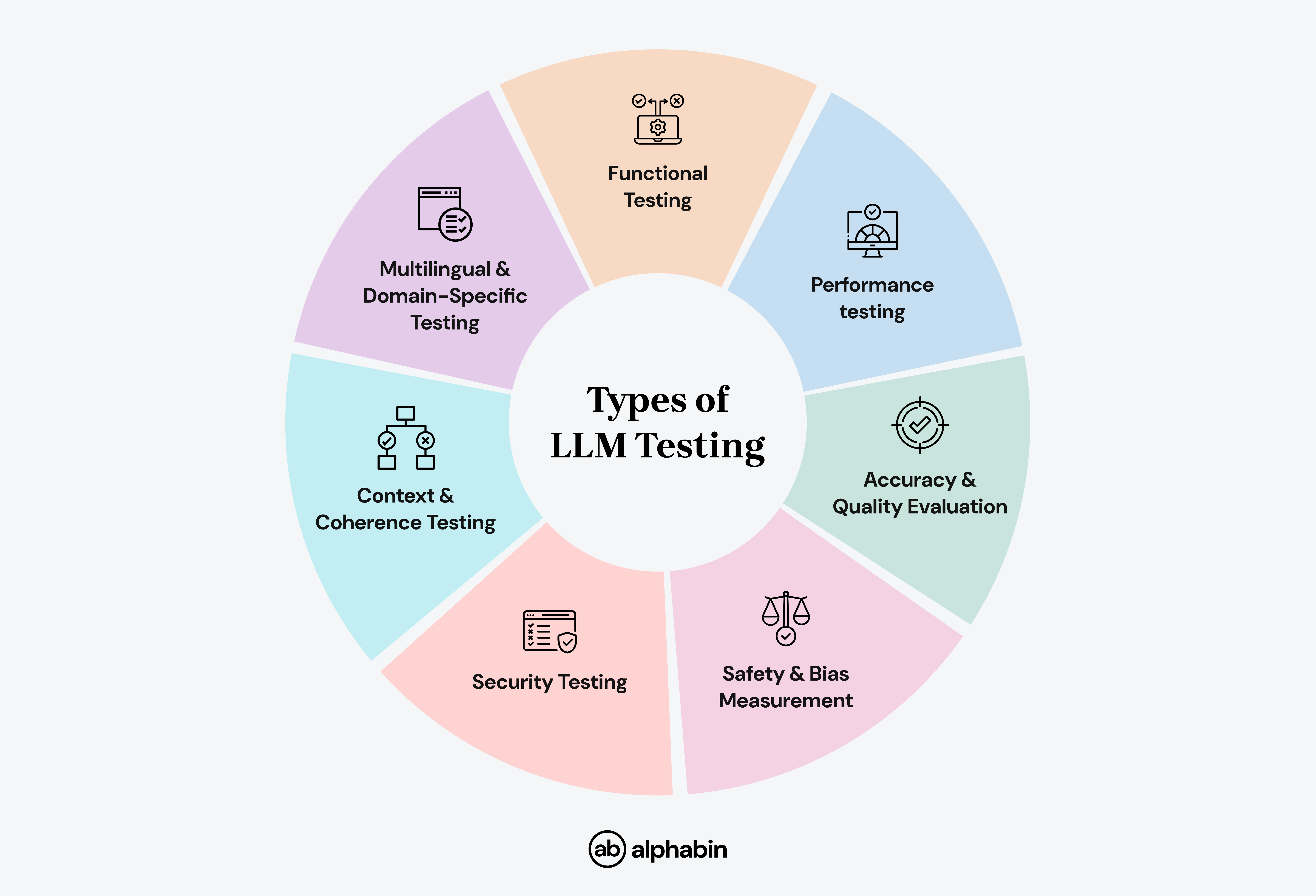
Types of LLM testing
Evaluating a Large Language Model (LLM) is not just about seeing if it works; it’s about using evaluation metrics to make sure you test LLM systems correctly, safely, equitably, and efficiently in work-like situations.
In 2025, LLM evaluation frameworks usually rest within these main categories:
Modern Testing Strategies and Frameworks
Modern methods for LLM testing have moved away from the old input-output testing to sophisticated validation frameworks to capture user behavior.
These frameworks combine automated testing with human evaluation, covering a minimally viable set of failure modes.
These frameworks not only evaluate model behavior but also support AI model validation, ensuring outputs remain accurate and reliable across real-world use cases.
A well-defined testing process is crucial for ensuring the reliability and robustness of testing applications that utilize LLMs. Specialized approaches are often required when testing applications that leverage LLMs.
Best LLM testing strategies
In 2025, effective LLM testing techniques include a multi-faceted process that mixes traditional software testing with various techniques dedicated to evaluating language models.
A structured LLM evaluation framework helps compare outputs consistently, measure bias, and verify safety, ensuring high-quality chatbot performance.
A layered approach, including some automated tests and some human-in-the-loop evaluation, is very important for obtaining reliable and trustworthy performance from any LLM.
{{blog-cta-2}}
Key LLM Testing Strategies in 2025:
1. Automated Testing Frameworks
Use tools like LLM Test Mate, Zep, FreeEval, RAGAs, and Deepchecks to validate outputs at scale with bias detection, semantic checks, and continuous monitoring.
2. Performance Evaluation
Measure quality with metrics such as hallucination detection, coherence, summarization accuracy, and bias. LLM-as-a-judge models give deeper insights into results.
3. Integration Testing
Verify how the LLM testing works with other systems and components to ensure smooth functionality and reliable data flow in complex applications.
4. Regression Testing
Run continuous tests after updates and verify smooth interaction with other systems to avoid failures in complex workflows.
Validate outputs through the Responsible AI principles to limit bias, toxicity, and harmful outputs, even for problematic inputs.
6. User Feedback & Human-in-the-Loop
Leverage user feedback and expert reviews to improve accuracy, fairness, and real-world relevance.
7. Prompt Engineering
Design clear, context-rich prompts for better test coverage. Techniques like prompt chaining, boundary value analysis, and domain-specific wording improve reliability.
Tools like AiZolo can help validate prompt behavior across multiple models side by side before production use.
8. Security Testing
Identify threats such as prompt injection, data leakage, and PII exposure. Mitigate your risks through sanitization, validation, and secure data handling to protect both systems and users.
{{cta-image}}
Top tools and frameworks
Many of these tools support performance and load testing, as well as monitoring resource utilization, which are essential for evaluating system efficiency and ensuring optimal operation of large language models.
The growing demand for reliable AI chatbot testing tools has led to the development of frameworks like EvalBot, DeepEval, FreeEval, and Orq.ai that combine automated and human in the loop testing.
Automated LLM Testing Best Practices
In 2025, effective LLM testing consists of both automated testing and manual testing as needed, with an emphasis on accuracy, security, and ethical considerations.
As large language models (LLMs) become more advanced, evaluating LLMs and optimizing model efficiency are essential best practices to ensure reliable, accurate, and high-performing AI systems.
Best practices include 2025:
- Merge automation with human reviews – Use automated metrics (e.g., BLEU, ROUGE, BERTScore) for quick checks, but augment that automated metric with human assessments to catch small errors.
- Test for safety and bias – Use the automated scans (e.g., DeepEval BiasMetric or Perspective API) to find potentially harmful, biased, or toxic output.
- Integrate into CI/CD pipelines – Make testing part of the development process so testing automatically happens with each model change before production.
- Automate performance checks – Identify load and latency tests to ensure the chatbot remains fast, stable, and non-crashing under heavy user load.
- Enable real-time monitoring – Use automated feedback loops to track issues like hallucinations, irrelevant answers, or delays after deployment.
{{cta-image-second}}
Optimizing performance and cost
In 2025, businesses need not only accurate and safe models but also efficient ways to test LLM systems fast and cost-efficiently.
A key strategy is prompt optimization, where carefully designed test prompts reduce unnecessary tokens and improve response efficiency. Combined with caching, this lowers costs during chatbot testing without compromising quality.
Another best practice is chatbot performance testing through load testing and stress testing. Load testing evaluates the application's ability to handle increased traffic and user interactions, while stress testing assesses robustness under extreme or high-load conditions.
These highlight resource-heavy operations and ensure the chatbot can handle peak demand reliably.
Monitoring resource utilization during these tests is crucial to optimizing costs and ensuring the system operates efficiently.
Finally, many teams are using smart routing, directing simple queries to smaller models and reserving larger LLMs for complex cases.
This balances performance with cost efficiency while maintaining a smooth user experience.
Key Challenges and Future Trends in LLM Testing
LLM capabilities evolve rapidly, creating new challenges that aren't addressed by conventional testing techniques. As models increase in complexity, the testing methods need to take advantage of the scale and complexity.
The main challenges when testing LLM include: promoting accuracy, avoiding misrepresentations, data privacy/security, and how evaluators may need to consider various tasks and contexts when testing LLM.

Common pitfalls to avoid
{{cta-image-third}}
Conclusion
In 2025, the ability to test LLM systems effectively is what sets successful businesses apart. As conversational AI becomes core to customer engagement, companies that prioritize chatbot testing and adopt advanced AI chatbot testing tools will lead in performance and trust.
With solutions like EvalBot by Alphabin, organizations can be confident that their chatbots will perform excellently in conversational AI testing and provide consistent chatbot performance testing.
Companies that adopt advanced conversational AI testing practices will ensure their chatbots deliver trustworthy, consistent results to users.
Organizations that view LLM testing as a strategic capability have an advantage in the future, turning testing from a challenge into a competitive advantage!
FAQs
1. What’s the difference between traditional software testing and LLM testing?
Traditional testing checks fixed outputs, while LLM testing deals with unpredictable, open-ended responses. It requires evaluation of accuracy, bias, and context.
2. How can I reduce the cost of chatbot performance testing?
Use prompt optimization, caching, and routing queries between smaller and larger models. This way can save costs without compromising quality.
3. How do I test LLMs for bias, hallucinations, and security risks?
Use tools for detecting bias, ground output with RAG (Retrieval-Augmented Generation), and adversarially evaluate responses to reveal exploitable weaknesses.
4. How often should I validate and monitor LLMs?
LLM testing isn’t one-time. Continuous validation and monitoring are needed to catch data drift, bias, and performance drops.


.svg)








.webp)




.svg)